В сети NFS основной объект для настройки производительности NFS - это сервер, однако некоторые параметры можно настраивать и на клиентах.
Поскольку один экземпляр (процесс) демона biod или nfsd может обрабатывать только один запрос одновременно и поскольку время ответа NFS обычно составляет значительную долю общего времени ответа, старайтесь избегать блокирования нитей по причине нехватки процессов демонов biod и nfsd.
Примечание: Начиная с AIX версии 4.2.1, каждый из демонов nfsd и biod представляет собой один многонитевый процесс (все нити принадлежат ядру). Новые нити создаются динамически по мере необходимости. Однако вы можете ограничить максимальное количество нитей процесса nfsd с помощью параметра nfs_max_threads команды nfso. Вы можете также ограничить максимальное число нитей процесса biod для одного монтирования с помощью опции монтирования biod.
Ниже приведены общие рекомендации по настройке демонов NFS:
Оптимальное число демонов nfsd и biod определяется последовательно, в несколько шагов. Приведенные ниже рекомендации могут служить не более чем начальными оценками.
Эти значения хорошо подходят для небольших систем, но должны быть увеличены, если число пользователей клиента или клиентов сервера превышает два. Рекомендации приведены ниже:
Определив оптимальное число демонов biod и nfsd, выполните следующие действия:
Изменить число демонов nfsd и biod можно с помощью команды chnfs.
Для установки числа демонов nfsd на сервере равным 10, как немедленно, так и при всех последующих загрузках системы, введите следующую команду:
# chnfs -n 10
Для временной установки числа демонов biod на клиенте равным 8 (до очередной перезагрузки) введите следующую команду:
# chnfs -N -b 8
Для установки числа демонов biod и числа демонов nfsd равным 9, начиная со следующей загрузки системы, введите следующую команду:
# chnfs -I -b 9 -n 9
Увеличение числа демонов biod на клиенте снижает производительность сервера, поскольку позволяет клиенту отправлять большее число запросов одновременно, что увеличивает нагрузку на сеть и сервер. В редких случаях, когда клиент перегружает сервер, рекомендуется сократить число демонов biod клиента до одного:
# stopsrc -s biod
В результате останется один процесс biod ядра.
При настройке каталогов NFS необходимо выбрать сильное (-o hard) или слабое (-o soft) монтирование. Если после успешного слабого монтирования каталога в работе возникает ошибка (обычно тайм-аут), сообщение о ней немедленно передается вызывающей программе. Если ошибка возникает при сильном монтировании, NFS повторяет операцию.
Постоянная ошибка при обращении к сильно смонтированному каталогу может сильно повлиять на производительность, поскольку большое число попыток (1000) и значение тайм-аута (0,7 секунды) по умолчанию в сочетании с тем, что значение тайм-аута увеличивается с каждой очередной попыткой, приводят к тому, что попытки выполнить операцию занимают слишком много времени.
Технически возможно снизить число повторов или увеличить значение тайм-аута с помощью опций команды mount. Однако значительное изменение этих параметров может привести к выдаче избыточных сообщений об ошибках сильной связи. Вместо этого рекомендуется при монтировании каталогов указать опцию intr, позволяющую прервать цикл повторов с клавиатуры.
Хотя слабое монтирование каталогов позволяет обнаружить ошибку раньше, при нем велик риск повреждения данных. Для каталогов, для которых разрешено и чтение, и запись, следует применять сильное монтирование.
В команде mount предусмотрены дополнительные опции управления работой NFS. Эти опции часто игнорируются или применяются неправильно.
Перед применением опций монтирования определите, к каким показателям надежности и скорости обмена пакетами по сети между клиентом и сервером вы стремитесь. Применение опций монтирования каталогов NFS позволят уменьшить нагрузку на сервер и улучшить работу сети.
Опции монтирования каталогов NFS указываются в виде списка после опции -o команды mount. Элементы списка после опции -o разделяются запятыми без пробелов.
Наиболее часто применяются опции настройки размера блока чтения и записи. Эти опции задают максимальный размер блока чтения и записи для каждого RPC. Иногда требуется уменьшить значения в опциях rsize и wsize команды mount для сокращения размеров передаваемых пакетов. Это может потребоваться по двум причинам:
Уменьшение значений rsize и wsize может повысить скорость работы NFS в перегруженных сетях за счет сокращения времени подготовки каждого пакета. Побочный эффект состоит в увеличении количества пакетов и, как следствие, нагрузки на сеть и процессоры сервера и клиента.
Если файловая система NFS работает в высокоскоростной сети, такой как SP Switch, производительность может быть повышена путем увеличения размера пакета чтения и записи. В NFS версии 3 значения rsize и wsize могут быть увеличены до 65536. Значение по умолчанию - 32768. В NFS версии 2 максимальные значения (они же - значения по умолчанию) rsize и wsize составляли 8192.
Если приложениями не используются Списки управления доступом (ACL) в смонтированной файловой системе, то вы можете снизить нагрузку на клиент и сервер, указав опцию noacl. Для этого введите следующую команду:
options=noacl
Укажите эту опцию в разделе файла /etc/filesystems, отвечающем за создание соответствующей файловой системы.
Опция retrans команды mount задает число повторных передач запроса NFS (значение по умолчанию - 3).
С выбором между слабым и сильным монтированием тесно связан вопрос об оптимальном значении тайм-аута для заданной конфигурации сети. Если сервер сильно загружен, соединен с клиентом через несколько мостов или шлюзов или работает по глобальной сети, значение тайм-аута по умолчанию может оказаться неподходящим. В этом случае клиент и сервер будут тратить свои ресурсы на ненужные повторы передачи. Например, если следующая команда:
# nfsstat -c
выдает большие значения (больше пяти процентов от общего количества) в полях timeouts и badxids, рекомендуется увеличить значение параметра timeo следующей командой SMIT:
# smitty chnfsmnt
Введите новое значение в строке Тайм-аут NFS в десятых долях секунды напротив нужного каталога.
Значение по умолчанию - 0,7 секунды (timeo=7), но это значение изменяется расширением ядра для поддержки NFS в зависимости от типа вызова. Для чтения, например, это значение удваивается, так что тайм-аут чтения по умолчанию равен 1,4 секунды.
Для управления значением timeo в клиентах с операционной системой версии 4 необходимо задать опцию nfs_dynamic_retrans команды nfso равной нулю. Выбор между увеличением или уменьшением timeo зависит от конкретного случая. Оптимальное значение должно быть достаточным для своевременной доставки пакета в обе стороны и обработки запроса.
Если пакеты приходят без потерь, но с задержками, то для устранения излишних повторных передач значение timeo нужно увеличить.
Если пакеты теряются и никогда не достигают адресата, то их ожидание - это пустая трата времени, поэтому значение timeo нужно уменьшить.
Для выбора оптимального значения введите команду nfsstat -cr в системе клиента и обратите внимание на значение в столбце badxid. Оно указывает число полученных клиентом ответов RPC, не соответствующих никакому активному запросу. Обычно это означает, что в результате повторной передачи запроса клиент получил два одинаковых ответа. В этом случае значение timeo должно быть увеличено.
Кроме того, определить причины снижения производительности можно с помощью анализатора сети. Если он отсутствует, попробуйте несколько раз изменить значение timeo и выясните, как это влияет на производительность. В некоторых случаях определить зависимость не удается. В этом случае рекомендуется определить причину задержки и потери пакетов и устранить неполадку.
В случае межсетевой передачи через мост попробуйте установить значение тайм-аута равным 50 (0,5 секунды). В случае глобальной сети установите значение 200. Через некоторое время (но не ранее чем через день) просмотрите статистические данные NFS. Если статистика вновь покажет существенный объем излишних повторных передач, увеличьте значение timeo в полтора раза и повторите проверку. При этом обратите внимание на загрузку серверов, мостов и маршрутизаторов - ни один элемент сети не должен быть перегружен.
Если клиент NFS сообщает об отброшенных пакетах, возникает сложная задача по поиску сетевого расположения, на котором это происходит. Пакеты могут отбрасываться клиентом, сервером или в любой промежуточной точке сети.
Пакеты редко теряются клиентом. Поскольку обычно вызовы RPC выполняются синхронно, т.е. каждый следующий шаг начинается только после получения ответа на предыдущий вызов, исчерпание ресурсов системы клиента маловероятно. Наибольший поток данных может быть принят системой после запроса на чтение - до 1 Мб/с и больше. Хотя объем данных может быть большим, число одновременных вызовов RPC обычно невелико, причем каждый демон biod заранее выделяет память для ответа. Все это уменьшает вероятность отбрасывания пакетов клиентом.
Обычно пакеты теряются в сети или сервером.
Перегруженные серверы могут терять пакеты в двух местах:
Если сервер NFS отвечает на очень большое число запросов, может произойти переполнение очереди вывода драйвера интерфейса. Такие ситуации можно обнаружить по статистике, которую можно просмотреть с помощью команды netstat -i. Обращайте внимание на любые ненулевые значения в столбцах Oerrs. Каждое событие в столбце Oerrs означает один потерянный пакет. Для устранения таких ситуаций достаточно увеличить очередь вывода драйвера. Слишком длинные очереди передачи увеличивают задержку при обработке сообщений. Однако, поскольку NFS поддерживает уникальный XID для каждого вызова, повторный вызов может быть удовлетворен ответом на исходный запрос. Кроме того, задержки, связанные с нахождением в очереди, существенно меньше задержек, связанных с повторной передачей запроса.
Вторая возможная точка потери пакетов - это буфер сокета UDP. Потерянные пакеты подсчитываются на уровне UDP, соответствующая статистика выдается командой netstat -p udp. Обратите внимание на значения в строке Число переполнений буфера сокета раздела UDP:.
Обычно пакеты NFS теряются в буфере сокета только при большом объеме операций записи, проходящих через NFS. Сокет сервера NFS подключен к порту 2049, и все входящие данные буферизуются этим портом UDP. Размер буфера по умолчанию составляет 60 000 байт. Если это число разделить на размер записываемого пакета NFS по умолчанию (8192), то окажется, что восьми одновременных запросов на запись достаточно для переполнения буфера. Такая ситуация может возникнуть уже при двух клиентах NFS (с конфигурациями по умолчанию).
Переполнение буфера может быть связано либо с большим объемом передаваемых данных, либо с резкими перепадами в передаче.
Действия, которые следует предпринять в этих ситуациях, различны.
В некоторых случаях устранение потерь пакетов в буферах сокетов и очереди драйвера не приводит к исчезновению тайм-аутов и повторных передач со стороны клиента. Здесь также возможны два варианта. Если сервер перегружен, то это может повлиять на работу демонов nfsd и привести к тому, что время ответа будет превышать значение тайм-аута. Подробнее см. раздел Справочная таблица по настройке NFS. Другая распространенная причина, наиболее вероятная при низкой загруженности сервера, - потеря пакетов в сети.
Если на сервере не наблюдается переполнений буфера сокета и очереди интерфейса, клиент часто выполняет повторные передачи, но сервер не перегружен, то пакеты могут теряться сетью. В данной ситуации под сетью имеется в виду следующее: структура, состоящая из физического носителя сигналов, сетевых устройств (таких как маршрутизаторы, мосты и концентраторы) и прочего аппаратного и программного обеспечения, реализующего передачу пакетов между клиентом и сервером.
Низкая производительность NFS в то время, когда сервер не перегружен и не отбрасывает пакеты, указывает на потери пакетов в сети. Подтверждение этого предположения и обнаружение причин неполадок в сети - сложная задача. Решать ее рекомендуется в зависимости от физической удаленности клиента от сервера и объема доступных ресурсов.
Иногда клиент и сервер находятся достаточно близко, чтобы между ними можно было установить прямое соединение. Если это устраняет все неполадки, то, очевидно, причина неполадок кроется в самой сети. Однако такой эксперимент возможен не всегда.
В каждой клиентской системе NFS поддерживает кэш для атрибутов файлов и каталогов, использовавшихся недавно. Устанавливаемые в файле /etc/filesystems пять параметров позволяют задать время хранения записей в кэше. Эти параметры приведены ниже:
После каждого обновления файла или каталога удаление информации о нем из кэша откладывается минимум на acregmin или acdirmin секунд. Если это повторное обновление, то удаление информации из кэша будет отложено на интервал между двумя обновлениями, но не более чем на acregmax или acdirmax секунд.
NFS не кэширует данные, но страницы данных NFS кэшируются Администратором виртуальной памяти (VMM) так же, как и страницы данных локального диска. Если система выполняет функции выделенного сервера NFS, то для увеличения производительности можно настроить VMM таким образом, чтобы под кэширование данных использовалась вся свободная память. Для этого параметру maxperm, отвечающему за объем памяти под страницы файлов, необходимо присвоить значение 100 процентов:
# vmtune -P 100
Аналогичный способ может применяться и на клиентах NFS, но он будет допустим только в том случае, если программам требуется небольшой объем памяти.
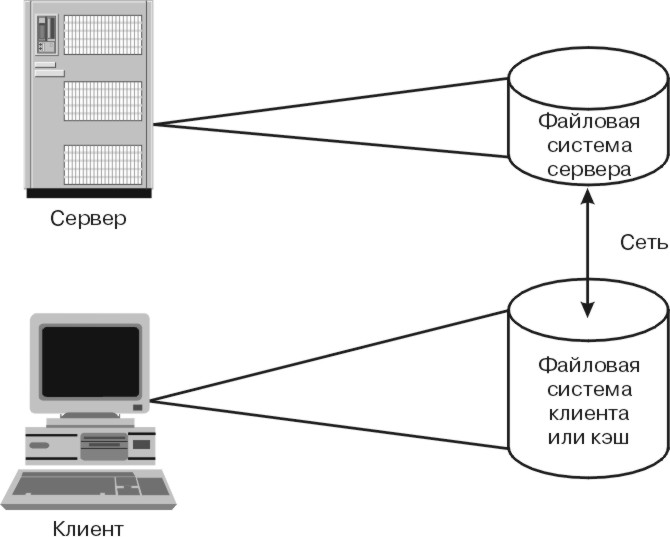
Для повышения производительности удаленных файловых систем и медленнодействующих устройств, таких как дисководы CD-ROM, может применяться Кэширующая файловая система (CacheFS). В случае ее применения данные, считанные из удаленной файловой системы или с компакт-диска, сохраняются в кэше локальной системы, что обеспечивает немедленный доступ к ним при втором обращении. Алгоритм работы кэша CacheFS работает заключается в отображении исходной файловой системы (например NFS) на некоторую целевую (локальную), как показано на следующем рисунке:
Рис. 10-3. Кэширующая файловая система (CacheFS). На этом рисунке показаны клиент и сервер, соединные по сети. На дисках сервера располагается серверная файловая система. На дисках сервера располагается кэшированная, или клиентская файловая система.
Учтите, что в AIX версии 4.3 в качестве исходной файловой системы поддерживается только NFS версии 2 или 3, а качестве целевой - только JFS.
CacheFS работает следующим образом:
Например, CacheFS позволяет хранить компоненты CAD на сервере, а клиентам работать с их локальными кэшированными копиями.
CacheFS не поддерживает чтение и запись файлов размером больше 2 Гб.
Поскольку все данные после получения с сервера кэшируются, скорость выполнения запросов к файловой системе существенно увеличивается. Небольшие объемы данных могут храниться в памяти клиента, поэтому преимущества кэширующей файловой системы проявляются в основном при работе с большими объемами данных. Дополнительное преимущество состоит в том, что данные остаются в кэше и после перезапуска системы, в то время как данные, находящиеся в страницах памяти, при этом теряются.
Производительность NFS может быть ограничена "медленными" сетями или перегруженным сервером. В этом случае непосредственная работа клиентов с сервером будет медленной. CacheFS не ускоряет первое обращение к данным, но ускоряет обработку всех последующих запросов к тем же данным, которые выполняются без участия сервера и передачи по сети.
По мере увеличения объема данных в кэш-памяти клиентов нагрузка на сервер NFS уменьшается. Это означает, что сервер может обслуживать больше клиентов.
Уменьшение числа запросов, передаваемых по сети, снижает нагрузку на сеть, высвобождая ее для других задач.
Не каждое приложение выиграет от применения CacheFS. Поскольку CacheFS повышает только производительность чтения, ее применение эффективно только для приложений, много раз считывающих одни и те же данные. Примером могут служить программы САПР, часто обращающиеся к большим моделям при вычислениях.
Тесты производительности показывают, что последовательное чтение из кэширующей файловой системы в 2,4 - 3,4 раза быстрее чтения непосредственно из NFS.
CacheFS не повышает производительность записи. Однако при монтировании файловой системы CacheFS командой mount вы можете указать в опции -o два параметра, управляющих записью. Они влияют на производительность последующего чтения данных. Описание этих параметров приведено ниже:
Поскольку результаты небольших операций чтения сохраняются в памяти в любом случае, их кэширование на диске не повышает производительность. Также при кэшировании не повышается производительность неупорядоченного чтения различных блоков данных, кроме случаев повторного обращения к тем же блокам.
Первый запрос на чтение отправляется серверу, поскольку данные кэшируются только после получения запроса от пользователя. Поэтому первый запрос на чтение выполняется с обычной скоростью NFS. Все последующие запросы к тем же данным выполняются со скоростью доступа к JFS.
Актуальность данных в кэше проверяется периодически, с некоторым интервалом. Поэтому кэшировать часто изменяющиеся данные опасно. Рекомендуется применять CacheFS для кэширования только неизменяемых или редко изменяемых данных.
Производительность записи при кэшировании NFS различна в версиях 2 и 3. Тесты производительности показывают, что:
Файловая система CacheFS не создается по умолчанию и не может быть создана автоматически при создании файловой системы NFS.
Для повышения производительности записи в кэшированной NFS при работе в AIX версии 4.3.1 необходимо установить набор файлов уровня 4.3.1.1.
Системный администратор должен явно указать кэшируемые файловые системы. Выполните следующие действия:
# cfsadmin -c -o параметрыкаталог
где параметры - это параметры выделения ресурсов, а каталог - имя каталога, в котором будет создан кэш.
# mount -V cachefs -o backfstype=nfs,cachedir=/каталог-кэширования remhost:/удаленный-хост:/каталог локальная_точка_монтирования
где удаленный-хост:/каталог - это имя удаленного хоста и файловой системы, в которой находятся данные, а локальная точка монтирования - точка монтирования в системе клиента, в которой будут доступны данные из удаленной файловой системы.
При создании кэширующей файловой системы можно задать несколько параметров:
Для передачи по сети NFS применяет протоколы UDP и TCP. Их настройка описана в разделах Настройка производительности TCP и UDP и Настройка производительности пула буферов mbuf. В частности, вы должны выполнить следующие действия:
При настройке UDP вы можете обнаружить, что команда netstat -s показывает существенное количество переполнений буфера сокетов UDP. Как и при обычной настройке UDP, увеличьте в этом случае значение sb_max. Кроме того, необходимо увеличить значение nfs_socketsize, управляющее размером буфера сокетов NFS. Пример:
# no -o sb_max=131072 # nfso -o nfs_socketsize=130972
В этом примере параметру sb_max присваивается значение по крайней мере на 100 байт больше, чем параметру nfs_socketsize, а последнему присваивается значение 130972.
Примечание: В AIX версии 4 размер буфера сокета задается динамически. Настройку с помощью команд no и nfso следует повторять при каждой загрузке системы. Добавьте их в файл /etc/rc.net или /etc/rc.nfs сразу после команд запуска демонов nfsd и biod. Расположение этих команд существенно.
Производительность серверов NFS, обрабатывающих много запросов на запись, может быть повышена путем вынесения логического тома журнала на отдельный от томов данных физический том. Дополнительная информация приведена в разделе Рекомендации по подготовке к установке, касающиеся дисков.
Часто требуется обеспечить параллелизм доступа к данным. Одновременный доступ к одной файловой системе нескольких клиентов или нескольких процессов одного клиента может привести к перегрузке дискового устройства сервера. Узнать степень загруженности дисков можно с помощью команды iostat.
Общая стратегия для больших серверов NFS состоит в распределении нагрузки дискового ввода-вывода по максимально возможному числу дисков и контроллеров. Таким образом обеспечивается параллельная работа наибольшего числа демонов nfsd. В системе с оптимальным распределением нагрузки дискового ввода производительность в отдельные моменты может быть ограничена лишь быстродействием процессоров.
Многие случаи неправильного применения NFS связаны с непониманием того факта, что доступ к файлам этой файловой системы осуществляется по дорогостоящему и медленнодействующему сетевому соединению. Несколько примеров приведены ниже:
Возможны разные мнения по поводу того, насколько правильным является подобное использование возможностей NFS. Однако не вызывает сомнений, что во всех этих примерах за удобство использования пришлось заплатить избыточной загрузкой процессоров и сети, т.е. снижением общей производительности. Если при нормальной работе системы необходим доступ по NFS, то при планировании конфигурации необходимо постараться достичь максимального эффекта за счет разумного компромисса между техническими и деловыми преимуществами различных вариантов. Например:
Другой пример приложения, которое не должно работать с файлами NFS, - это приложение, запускающее сотни вызовов lockf() и flock() в секунду. В файловой системе NFS все вызовы lockf() и flock() (а также любые другие запросы на блокировку файлов) выполняются демоном rpc.lockd. Это существенно снижает производительность системы, поскольку демон блокировки не в состоянии обрабатывать запросы с такой частотой.
Независимо от производительности клиента и сервера, все операции через NFS будут выполняться медленнее обычных. Это происходит по нескольким причинам, но все они связаны с тем, что при чтении и записи в блокированный файл принимаются специальные меры для обеспечения синхронности. Это означает, что не кэшируются никакие данные файла, включая его атрибуты. Все операции с файлом выполняются синхронно без кэширования. Блокирование приложением файлов, доступных через сеть, можно обнаружить по резкому снижению производительности по сравнению с другими приложениями, работающими с теми же файлами.
Ниже приведена справочная таблица по настройке производительности NFS:
Признак такой ситуации - повышение производительности при замедлении работы клиента. Для этого могут независимо применяться следующие методы:
Поверьте работу с одним экземпляром демона biod в системе клиента. Если быстродействие увеличилось, сеть или сервер были перегружены. Для завершения всех дополнительных экземпляров демонов biod введите команду stopsrc -s biod. Останется работать один процесс biod, принадлежащий ядру. Проверьте производительность. Если она не повысилась, перезапустите демоны biod командой startsrc -s biod. В противном случае определите источник потери пакетов при работе с полным набором демонов. Это может быть сеть, сетевое устройство или медленнодействующий, перегруженный или неправильно настроенный сервер.
Чаще всего на производительность серверов NFS влияют именно эти ошибки, тесно связанные с конфигурацией.
Если в столбце Oerrs указано непустое значение, увеличьте очереди передачи сетевого интерфейса. Для этого не требуется выключать систему, но необходимо отсоединить интерфейс (rmdev -l). Последнее действие невозможно в бездисковой системе, либо если интерфейс занят другими задачами. В этом случае с помощью команды chdev внесите в ODM изменения, которые вступят в силу при следующей загрузке. Начните с удвоения длины очереди и затем увеличивайте длину очереди каждый раз на 30 до тех пор, пока ошибки Oerrs не исчезнут. В системах SP2, в которых NFS работает через высокоскоростной коммутатор, ошибки Oerrs могут вызываться коммутатором в случае его сбоя или временной недоступности. Значение Oerrs увеличивается при каждой неудачной попытке передать пакет коммутатору. Устранить эти ошибки с помощью настройки невозможно.
Большое значение этого поля указывает на неполадку.
При работе с протоколом UDP причиной снижения производительности нередко бывает регулярное переполнение буферов на сервере. В сильно загруженных системах могут переполняться и буферы TCP. В этой главе будет описана только настройка UDP, настройка TCP выполняется аналогично.
Введите команду netstat -s и выясните число переполнений буфера сокетов UDP. На неполадку указывает любое ненулевое число. Учтите, однако, что не все указанные переполнения буфера сокетов UDP могли быть вызваны NFS. Для определения вклада NFS в это число сравните его с числом потерянных пакетов в системе клиента, которое выдается командой nfsstat -cr. Проверьте зависимость между этими числами во время интенсивной записи в NFS.
Переполнения буфера сокетов могут возникать на перегруженных или "медленных" по сравнению с клиентами серверах. До 10 переполнений буфера сокетов, как правило, не сильно влияют на производительность. Увеличение этого числа на порядок может оказать заметное влияние на проивзодительность. Если число переполнений быстро растет, в то время как производительность NFS низка, то систему необходимо настроить.
Снизить число переполнений буфера сокетов NFS можно двумя способами. Во-первых, попробуйте увеличить число демонов nfsd в системе сервера. Если это не устранит неполадку, необходима настройка двух переменных ядра: sb_max (максимальный размер буфера сокета) и nfs_socketsize (размер буфера сокетов NFS). Значение переменной sb_max можно увеличить с помощью команды no. Значение переменной nfs_socketsize можно увеличить с помощью команды nfso.
Параметр sb_max должен быть больше параметра nfs_socketsize. Определить оптимальные значения нелегко. Старайтесь минимизировать размер буфера при условии, чтобы команда netstat показывала нулевое или небольшое число переполнений.
Учтите, что в AIX версии 4 размер буфера сокета задается динамически. Настройку с помощью команд no и nfso следует повторять при каждой загрузке системы. Добавьте их в файл /etc/rc.nfs сразу после команд запуска демонов biod, но до команд запуска демонов nfsd. Расположение этих команд существенно.
Проверьте наличие отклоненных или задержанных запросов на получение буферов mbuf. Возможно, требуется увеличение числа буферов mbuf. Дополнительная информация о настройке пула буферов mbuf приведена в разделе Настройка производительности пула буферов mbuf.
Изредка неполадки объясняются слишком коротким интервалом между пакетами. Если между клиентом и сервером находится маршрутизатор или другое устройство, ознакомьтесь с документацией к этому устройству и выясните, нельзя ли изменить интервал между пакетами. Если это возможно, попробуйте увеличить его.
Маршрутизатор может терять пакеты при передаче их из "быстрой" сети в "медленную". Например, такая ситуация наблюдалась при получении маршрутизатором пакетов по сети FDDI и отправке их по сети Ethernet. Маршрутизатор не успевал передавать пакеты через Ethernet с той же скоростью, с какой он получал их по FDDI. Решение заключается в замедлении работы клиента, уменьшении размера блоков чтения-записи и ограничении числа демонов biod, работающих с одной файловой системой.
Запустите команду netstat -i и найдите значения MTU на клиенте и на сервере. Если они различны, попробуйте приравнять их и проверьте производительность. Учтите, что при передаче по "медленным" и глобальным сетям может происходить дополнительная фрагментация пакетов. Определите минимальный размер MTU на пути между сервером и клиентом и укажите в параметрах rsize и wsize меньшее значение.
С помощью команды traceroute проверьте маршрут пакета.
Запустите команду errpt и убедитесь в отсутствии записей о неполадках сетевого устройства и носителя. Убедитесь также в отсутствии ошибок дисковых накопителей - они могут влиять на производительность сервера NFS при работе с экспортированными файловыми системами.